Archive Site Provided for Historical Purposes
Begun formally in 1990, the U.S. Human Genome Project was a 13-year effort coordinated by the U.S. Department of Energy (DOE) and the National Institutes of Health (NIH; http://www.genome.gov/). The project originally was planned to last 15 years, but rapid technological advances accelerated the completion date to 2003. Project goals
To help achieve these goals, researchers also studied the genetic makeup of several nonhuman organisms. These include the common human gut bacterium Escherichia coli, the fruit fly, and the laboratory mouse.
A unique aspect of the U.S. Human Genome Project is that it was the first large scientific undertaking to address potential ELSI implications arising from project data. DOE and NIH Genome Programs set aside 3% to 5% of their respective annual HGP budgets for the study of these issues. Nearly $1 million was spent on HGP ELSI research.
Another important feature of the project was the federal government's long-standing dedication to the transfer of technology to the private sector. By licensing technologies to private companies and awarding grants for innovative research, the project catalyzed the multibillion-dollar U.S. biotechnology industry.
For more background information on the U.S. Human Genome Project, see the following
| U.S. Human Genome Project Funding | |||
|---|---|---|---|
| ($Millions) | |||
| FY | DOE | NIH* | U.S. Total |
| 1988 | 10.7 | 17.2 | 27.9 |
| 1989 | 18.5 | 28.2 | 46.7 |
| 1990 | 27.2 | 59.5 | 86.7 |
| 1991 | 47.4 | 87.4 | 134.8 |
| 1992 | 59.4 | 104.8 | 164.2 |
| 1993 | 63.0 | 106.1 | 169.1 |
| 1994 | 63.3 | 127.0 | 190.3 |
| 1995 | 68.7 | 153.8 | 222.5 |
| 1996 | 73.9 | 169.3 | 243.2 |
| 1997 | 77.9 | 188.9 | 266.8 |
| 1998 | 85.5 | 218.3 | 303.8 |
| 1999 | 89.9 | 225.7 | 315.6 |
| 2000 | 88.9 | 271.7 | 360.6 |
| 2001 | 86.4 | 308.4 | 394.8 |
| 2002 | 90.1 | 346.7 | 434.3 |
| 2003 | 64.2 | 372.8 | 437 |
Note: These numbers do not include construction funds, which are a very small part of the budget.
* For an explanation of the NIH budget, contact the Office of Human Genome Communications, National Human Genome Research Institute [https://www.genome.gov/], National Institutes of Health.
A genome is all the DNA in an organism, including its genes. Genes carry information for making all the proteins required by all organisms. These proteins determine, among other things, how the organism looks, how well its body metabolizes food or fights infection, and sometimes even how it behaves.
DNA is made up of four similar chemicals (called bases and abbreviated A, T, C, and G) that are repeated millions or billions of times throughout a genome. The human genome, for example, has 3 billion pairs of bases.
The particular order of As, Ts, Cs, and Gs is extremely important. The order underlies all of life's diversity, even dictating whether an organism is human or another species such as yeast, rice, or fruit fly, all of which have their own genomes and are themselves the focus of genome projects. Because all organisms are related through similarities in DNA sequences, insights gained from nonhuman genomes often lead to new knowledge about human biology.
The current consensus predicts about 20,500 genes, but this number has fluctuated a great deal since the project began.
The reason for so much uncertainty has been that predictions are derived from different computational methods and gene-finding programs. Some programs detect genes by looking for distinct patterns that define where a gene begins and ends ("ab initio" gene finding). Other programs look for genes by comparing segments of sequence with those of known genes and proteins (comparative gene finding). While ab initio gene finding tends to overestimate gene numbers by counting any segment that looks like a gene, comparative gene finding tends to underestimate since it is limited to recognizing only those genes similar to what scientists have seen before. Defining a gene is problematic because small genes can be difficult to detect, one gene can code for several protein products, some genes code only for RNA, two genes can overlap, and many other complications (5).
Even with improved genome analysis, computation alone is simply not enough to generate an accurate gene number. Clearly, gene predictions have to be verified by labor-intensive work in the laboratory (6).
Here's a brief history of the changes in gene number over time.
2007: 20,500
The 20,500 number of protein-coding genes was presented in a 2007 PNAS paper. Scientists arrived at this number by excluding the (now thought to be functionally meaningless, random occurrences) Open-Reading Frames (ORFs) that were included in the 2003 estimate of 24,500 genes. [M. Clamp et al., 2007. "Distinguishing Protein-Coding and Noncoding Genes in the Human Genome," PNAS 104(49), 19428-19433.]
2004: 20,000-25,000
October 2004 findings from The International Human Genome Sequencing Consortium, led in the United States by the National Human Genome Research Institute (NHGRI) and the Department of Energy (DOE), reduce the estimated number of human protein-coding genes from 35,000 to only 20,000-25,000, a surprisingly low number for our species. At that time, Consortium researchers had confirmed the existence of 19,599 protein-coding genes in the human genome and identified another 2,188 DNA segments that are predicted to be protein-coding genes. [International Human Genome Sequencing Consortium. 2004. "Finishing the Euchromatic Sequence of the Human Genome," Nature 431, 931-945.]
2003: 24,500 or fewer
In 2003, estimates from gene-prediction programs suggested there might be 24,500 or fewer protein-coding genes. The Ensembl genome-annotation system estimated them at 23,299. [Pennisi, E. 2003. "Gene Counters Struggle to Get the Right Answer," Science 301, 1040-1041.]
2003: Gene Sweep
Although the exact number of human genes was still uncertain, a winner of GeneSweep was announced in May 2003. GeneSweep was an informal gene-count betting pool that began at the 2000 Cold Spring Harbor Laboratory Genome Meeting. Bets ranged from around 26,000 to more than 150,000 genes. Since most gene-prediction programs were estimating the number of protein-coding genes at fewer than 30,000, GeneSweep officials decided to declare the contestant with the lowest bet (25,947 by Lee Rowen of the Institute of Systems Biology in Seattle) the winner. [Pennisi, E. 2003. "A Low Number Wins the GeneSweep Pool," Science 300, 1484.]
2001: 42,000
This number was based on a study by Dr. Michael P. Cooke, Dr. John B. Hogenesch, and colleagues at the Genomics Institute of the Novartis Research Foundation. They theorized in the study that there was incomplete overlap between estimates of predicted genes made by Celera and by the Human Genome Sequencing Consortium. [J. Hogenesch et al, 2001. "A Comparison of the Celera and Ensembl Predicted Gene Sets Reveals Little Overlap in Novel Genes," Cell 106, 413–415.] and Followup Letter: [Mark J. Daly, 2002. "Estimating the Human Gene Count," Cell 109, 283–284.]
2001: 65,000-75,000
An analysis by scientists at Ohio State University suggested between 65,000 and 75,000 human genes. This number was arrived at "based on the integration of public transcript, protein, and mapping information, supplemented with computational prediction." [Wright, F., et al. 2001. "A Draft Annotation and Overview of the Human Genome," Genome Biology 2, 1-18.] and [Briggs, H. 2001. "Dispute Over Number of Human Genes," BBC News Online.]
2001: 30,000-40,000
When analysis of the draft human genome sequence was published by the International Human Genome Sequencing Consortium on February 15, 2001, the paper estimated only about 30,000 to 40,000 protein-coding genes, much lower than previous estimates of about 100,000. This lower estimate came as a shock to many scientists because counting genes was viewed as a way of quantifying genetic complexity. With about 30,000, the human gene count would be only one-third greater than that of the simple roundworm C. elegans, which has about 20,000 genes. [Claverie, J. 2001. "Gene Number. What if There are Only 30,000 Human Genes?" Science 291, 1255–7.] and [E.W. Lander et al., "Initial sequencing and analysis of the human genome," Nature, 409, 860-921, 2001.] and [J.C. Venter et al., "The sequence of the human genome," Science, 291, 1304-51, 2001.]
2000: 120,000
Liang et al. 2000. "Gene index analysis of the human genome estimates approximately 120,000 genes," Nat. Genet. 25, 239–240.
The human genome reference sequences do not represent any one person’s genome. Rather, they serve as a starting point for broad comparisons across humanity. The knowledge obtained from the sequences applies to everyone because all humans share the same basic set of genes and genomic regulatory regions that control the development and maintenance of their biological structures and processes.
In the international public-sector Human Genome Project (HGP), researchers collected blood (female) or sperm (male) samples from a large number of donors. Only a few samples were processed as DNA resources. Thus donors' identities were protected so neither they nor scientists could know whose DNA was sequenced. DNA clones from many libraries were used in the overall project.
Technically, it is much easier to prepare DNA cleanly from sperm than from other cell types because of the much higher ratio of DNA to protein in sperm and the much smaller volume in which purifications can be done. Sperm contain all chromosomes necessary for study, including equal numbers of cells with the X (female) or Y (male) sex chromosomes. However, HGP scientists also used white cells from female donors' blood to include samples originating from women.
In the Celera Genomics private-sector project, DNA from a few different genomes was mixed and processed for sequencing. DNA for these studies came from anonymous donors of European, African, American (North, Central, South), and Asian ancestry. The lead scientist of Celera Genomics at that time, Craig Venter, has since acknowledged that his DNA was among those sequenced.
Many polymorphisms—small regions of DNA that vary among individuals—also were identified during the HGP, mostly single nucleotide polymorphisms (SNPs). Most SNPs have no physiological effect, although a minority contribute to the beneficial diversity of humanity. A much smaller minority of polymorphisms affect an individual’s susceptibility to disease and response to medical treatments.
Although the HGP has been completed, SNP studies continue in the International HapMap Project [http://hapmap.ncbi.nlm.nih.gov/], whose goal is to identify patterns of SNP groups (called haplotypes, or “haps”). The DNA samples for the HapMap Project came from 270 individuals, including Yoruba people in Ibadan, Nigeria; Japanese in Tokyo; Han Chinese in Beijing; and the French Centre d’Etude du Polymorphisme Humain (CEPH) resource.
[Answer supplied by Dr. Marvin Stodolsky, formerly of the U.S. DOE Office of Science's Office of Biological and Environmental Research]
Many laboratories around the United States received funding from either the Department of Energy (DOE), the National Institutes of Health (NIH; http://www.genome.gov/), or both, for Human Genome Project research. The Human Genome Organisation (HUGO; http://www.hugo-international.org/) helped to coordinate international collaboration in the genome project. A list of the major U.S. and international Human Genome Project research sites can be found here.
Other individual researchers at numerous colleges, universities, and laboratories throughout the United States also received DOE and NIH funding for human genome research. At any given time, the DOE Human Genome Program funded about 200 separate principal investigators.
After the atomic bomb was developed and used, the U.S. Congress charged the Department of Energy's (DOE) predecessor agencies (the Atomic Energy Commission and the Energy Research and Development Administration) with studying and analyzing genome structure, replication, damage, and repair and the consequences of genetic mutations, especially those caused by radiation and chemical by-products of energy production. From these studies grew the recognition that the best way to study these effects was to analyze the entire human genome to obtain a reference sequence. Planning began in 1986 for DOE's Human Genome Program and in 1987 for the National Institutes of Health's (NIH) program. The DOE-NIH U.S. Human Genome Project formally began October 1, 1990, after the first joint 5-year plan was written and a memorandum of understanding was signed between the two organizations. For more information see Progress of the Human Genome Project and DOE Biological and Environmental Research Program.
Consistent with the goals of the Human Genome Project, the DOE Human Genome Program focused on the following:
Another important DOE goal was to foster research into the ethical, legal, and social implications (ELSI) of genome research. The DOE Human Genome Program ELSI component and the data it generated concentrated on two main areas: (1) privacy and confidentiality of personal genetic information, including its accumulation in large, computerized databases and databanks; and (2) development of educational materials and activities in genome science and ELSI, including curricula and TV documentaries, workshops, and seminars for targeted audiences. Other areas of interest include data privacy arising from potential uses of genetic testing in the workplace and issues related to commercialization of genome research results and technology transfer.
For more details on the Department of Energy's involvement, see the following:
Making the Project Possible
Its long-standing mission to understand and characterize the potential health risks posed by energy use and production led DOE to propose, in the mid-1980s, that all three billion bases of DNA from an "average" human should be sequenced. Technologies available before that time had not enabled the routine detection of extremely rare and often minute genetic changes resulting from radiation and chemical exposures.
The scientific foundation for DOE's Human Genome Initiative already existed at the national laboratories.
In 1986, DOE became the first federal agency to announce and fund a genome program.
Developing the Tools and Technologies for Success
[NOTE: The DOE investments described below helped make the Human Genome Project a success. Substantial investments by NIH and the Wellcome Trust in the U.K. were equally important, however, and should not be overlooked. In most cases, the DOE successes outlined below were the result of basic research programs. Research is an incremental process that learns from both the successes and failures of other research investments, including those at other agencies and organizations. In addition, no single instrument, technology, reagent, or protocol made high-throughput DNA sequencing possible, many contributors were responsible.]
DNA Sequencers
Research on capillary-based DNA sequencing contributed to the development of the two major DNA sequencing machines—the Perkin-Elmer 3700 and the MegaBace DNA sequencers. The MegaBace DNA sequencer was developed initially with DOE funds by Dr. Richard Mathies at U.C. Berkeley. The Perkin-Elmer 3700 was based, in part, on DOE-funded research by Dr. Norman Dovichi at the University of Alberta. These high-throughput instruments are one of the keys to the success of the genome project.
Fluorescent dyes
DNA sequencing originally used radiolabeled DNA subunits. DOE-funded research contributed to the development of fluorescent dyes that increased the accuracy and safety of DNA sequencing as well as the ability to automate the procedures.
DNA cloning vectors
Before large DNA molecules can be sequenced, they are cut into small pieces and multiplied, or cloned, into numerous copies using microbial-based "cloning" vectors. Today, the bacterial artificial chromosome (BAC) is the most commonly used vector for initial DNA amplification before sequencing. These cloning vectors were developed with DOE funds.
BAC-end sequencing
The widely agreed-upon strategy for sequencing the human genome is based on the use of BACs that carry fragments of human DNA from known locations in the genome. DOE-funded research at The Institute for Genomic Research in Rockville, Maryland, and at the University of Washington provided the sequencing community with a complete set of over 450,000 BAC-based genetic "markers" corresponding to a sequence tag every 3 to 4 kilobases across the entire human genome. These markers were needed to assemble both the draft and the final human DNA sequence.
GRAIL
GRAIL (Gene Recognition and Assembly Internet Link) is one of the most widely used computer programs for identifying potential genes in DNA sequence and for general DNA sequence analysis. This powerful analytical tool was developed with DOE funds by Dr. Ed Uberbacher at Oak Ridge National Laboratory. Although a number of gene-finding tools are now available for use, GRAIL led the way.
Reducing Costs and Speeding Up Sequencing
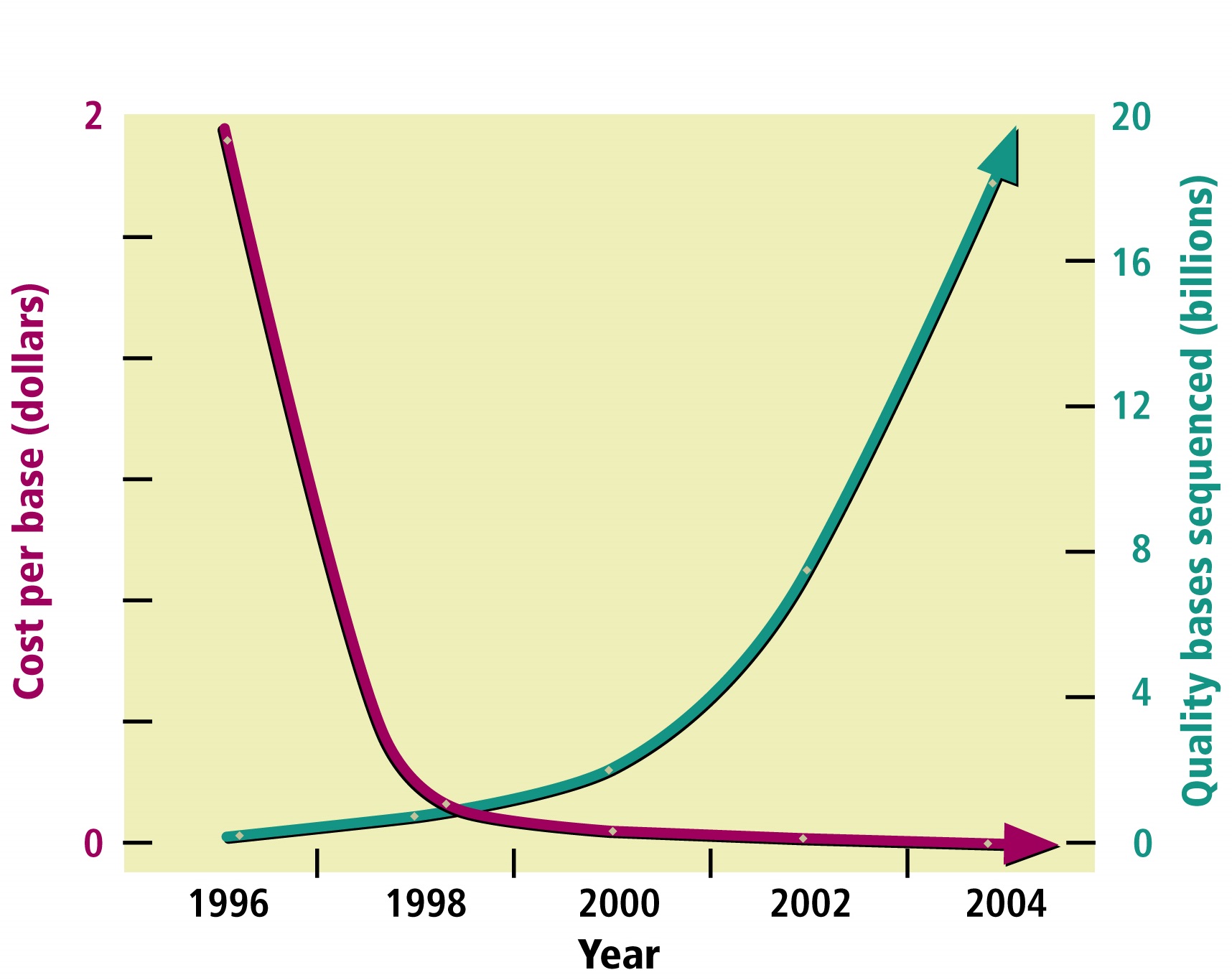
The above technological developments dramatically decreased DNA sequencing's cost while increasing its speed and efficiency. For example, it took 4 years for the international Human Genome Project to produce the first billion base pairs of sequence and less than 4 months to produce the second billion base pairs. In the month of January 2003, the DOE team sequenced 1.5 billion bases. The cost of sequencing has dropped dramatically since the project began and is still dropping rapidly.
The Human Genome Project (HGP) was an international 13-year effort, 1990 to 2003. Primary goals were to discover the complete set of human genes and make them accessible for further biological study, and determine the complete sequence of DNA bases in the human genome. See Timeline for more HGP history.

Published from 1989 until 2002, this newsletter facilitated HGP communication, helped prevent duplication of research effort, and informed persons interested in genome research.

 click to enlarge
click to enlarge