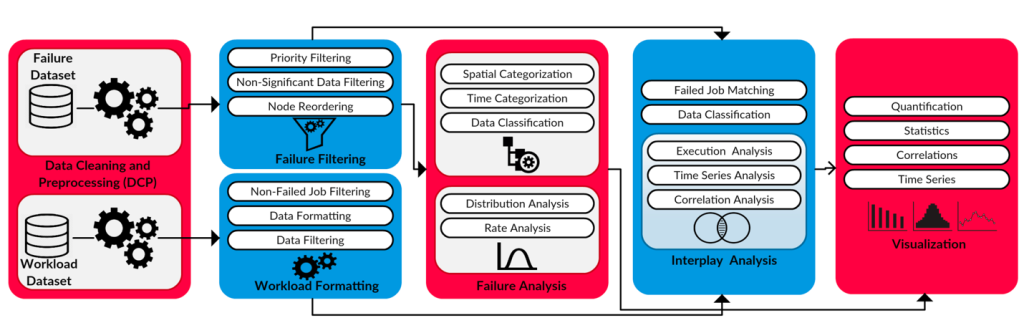
A team of researchers from Oak Ridge National Laboratory (ORNL and the Costa Rica Institute of Technology have published a study on the failures observed during the lifespan of a leadership class supercomputer. Powerful computing systems are addressing some of the most challenging problems in science and engineering, particularly in the intersection of simulation, data science, and artificial intelligence. An unintended consequence of the assemble of many components is the low reliability of the whole system. Creating a strong understanding of how these components fail and interact is fundamental in keeping top-level supercomputers efficient to push the boundaries of knowledge. The analysis of five years of reliability and workload data on a top-level supercomputer shows that user-generated failures are dominant, particularly those related to out-of-memory errors. The errors attributed to the hardware are mostly represented by GPU failures. However, both system and user failures follow different patterns according to multiple variables: trends in frequency, location, statistical modelling, timing, affected resources, and execution time duration before the crash. The paper proposes that there is still room for heavier theoretical reliability frameworks to be built on top of empirical evidence. Fault-tolerant software solutions, either at the system or user application level, should be designed and developed on such frameworks.

