Achievement: A multidisciplinary team of researchers from Oak Ridge National Laboratory (ORNL) pioneered the use of the LLVM-based high-productivity/high-performance Julia language unifying capabilities to write an end-to-end workflow on Frontier, the first US Department of Energy (DOE) exascale system.
Significance and Impact: Using Julia as a single paradigm paves a way to do productive science and improve the accessibility to leverage investments in high-performance computing (HPC) software: CPU/GPU computation, communication, parallel I/O and data analysis components using a scientific language to program our leadership facility systems. Currently, HPC programming is fragmented into compiled (Fortran, C, C++) and AI, data science ecosystems (Python) languages thus adding overhead to the research and development cycle from idea to publication. Our work showcased the feasibility, trade-offs, and benefits of Julia as a single language and ecosystem aiming at the intersection of high performance and high productivity on Frontier at scales not previously tested.
The work was awarded the best paper at the SC23 conference’s18th Workshop on Workflows in Support of Large-Scale Science (WORKS), it was also presented in the SC23 research poster track and was featured in the The Next Platform news outlet. Our intern experience as a contributor was highlighted at the SC23 main stage.
Research Details
- Problem: the current high-performance computing software landscape is divided into (i) compiled languages: e.g. Fortran, C, C++ for high-performance and (ii) high-level dynamic languages: e.g. Python, Matlab, R for data analysis and AI
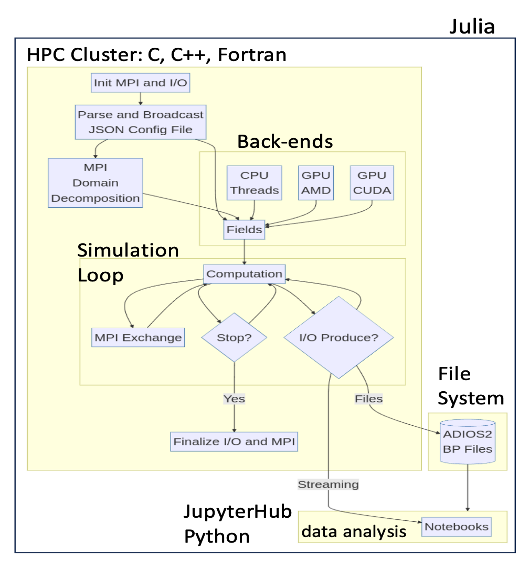
- We evaluated an entire end-to-end workflow on Frontier using Julia's HPC stack for: computation on AMD MI250x GPUs for a diffusion-reaction equation using a 7-point stencil kernel, MPI communication, parallel I/O using ADIOS2, and data analysis using Jupyter Notebooks
- Despite a reasonable LLVM-IR, Julia is still slower than a native HIP GPU kernel by 50%. Weak scaling showed negligible overheads for the Julia bindings to MPI and parallel I/O, on up to 512 nodes (4,092 GPUs), while online data analysis was possible on the facility’s JupyterHub portal.
- Some caveats: (i) underlying MPI failures were detected when running at roughly half of Frontier ~4K nodes, and (ii) the Just-in-Time (JIT) compiled nature of Julia adds some initial 10X overhead that is amortized over time.
- Overall, Julia shows promising language and ecosystem capabilities for HPC tasks while performance gaps still need to be close on AMD GPUs for the tested 7-point stencil kernel.
Facility: measurements and tests were conducted at the Oak Ridge Leadership Computing Facility (OLCF) Frontier supercomputer. This research used resources of the Experimental Computing Laboratory (ExCL) hosted at Oak Ridge National Laboratory.
Sponsor/Funding: The Exascale Computing Project and Bluestone, a X-Stack project in the DOE Advanced Scientific Computing Office.
PI and affiliation: Jeffrey S Vetter (ORNL)
Team: William F Godoy, Pedro Valero-Lara, Caira Anderson, Katrina W Lee, Ana Gainaru, Rafael Ferreira Da Silva, Jeffrey S. Vetter (ORNL)
Citation and DOI: William F. Godoy, Pedro Valero-Lara, Caira Anderson, Katrina W. Lee, Ana Gainaru, Rafael Ferreira Da Silva, and Jeffrey S. Vetter. 2023. Julia as a unifying end-to-end workflow language on the Frontier exascale system. In Proceedings of the SC '23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis (SC-W '23). Association for Computing Machinery, New York, NY, USA, 1989–1999. https://doi.org/10.1145/3624062.3624278
Summary: We evaluate Julia as a single language and ecosystem paradigm powered by LLVM to develop workflow components for high-performance computing. We run a Gray-Scott, 2-variable diffusion-reaction application using a memory-bound, 7-point stencil kernel on Frontier, the US Department of Energy’s first exascale supercomputer. We evaluate the performance, scaling, and trade-offs of (i) the computational kernel on AMD’s MI250x GPUs, (ii) weak scaling up to 4,096 MPI processes/GPUs or 512 nodes, (iii) parallel I/O writes using the ADIOS2 library bindings, and (iv) Jupyter Notebooks for interactive analysis. Results suggest that although Julia generates a reasonable LLVM-IR, a nearly 50% performance difference exists vs. native AMD HIP stencil codes on GPUs. We observed near zero overhead when using MPI and parallel I/O bindings for system-wide installed implementations. Consequently, Julia emerges as a compelling high-performance and high productivity workflow composition language, as measured on the fastest supercomputer in the world.





