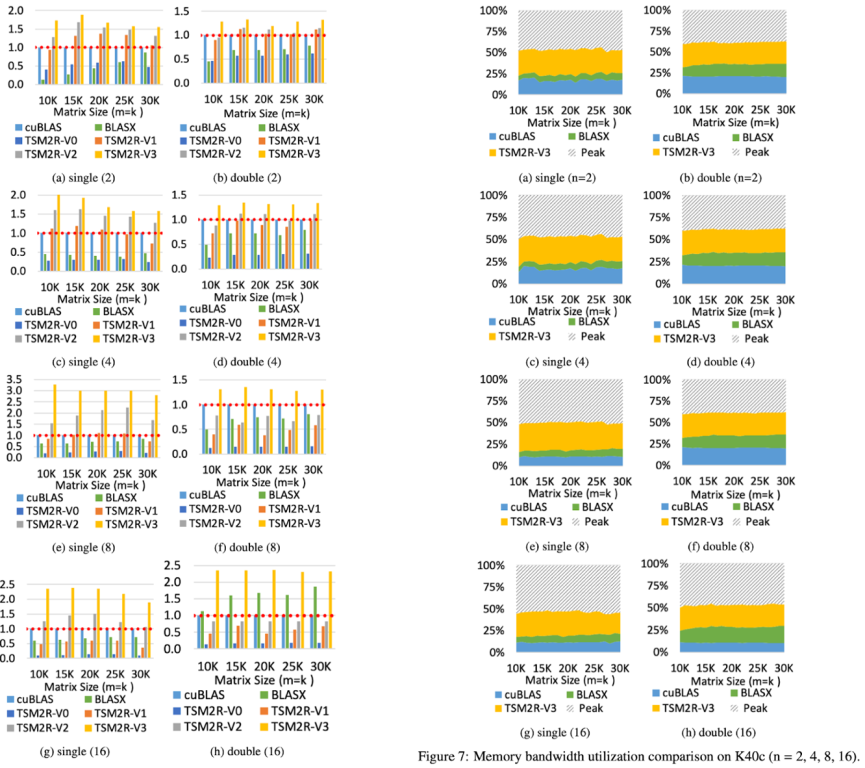
Linear algebra operations have been widely used in big data analytics and scientific computations. Many works have been done on optimizing linear algebra operations on GPUs with regular-shaped input. However, few works focus on fully utilizing GPU resources when the input is not regular-shaped. Current optimizations do not consider fully utilizing the memory bandwidth and computing power; therefore, they can only achieve sub-optimal performance. In this paper, we propose two efficient algorithms -- TSM2R and TSM2L -- for two classes of tall-and-skinny matrix-matrix multiplications on GPUs. Both of them focus on optimizing linear algebra operation with at least one of the input matrices is tall-and-skinny. Specifically, TSM2R is designed for a large regular-shaped matrix multiplying a tall-and-skinny matrix, while TSM2L is designed for a tall-and-skinny matrix multiplying a small regular-shaped matrix. We implement our proposed algorithms and test on several modern NVIDIA GPU micro-architectures. Experiments show that, compared to the current state-of-the-art works, (1) TSM2R speeds up the computation by 1.1x~3x and improves the memory bandwidth utilization and computing power utilization by 8%~47.6% and 7%~37.3%, respectively, when the regular-shaped matrix size is relatively large or medium; and (2) TSM2L speeds up the computation by 1.1x~3.5x and improve the memory bandwidth utilization by up to 55% when the regular-shaped matrix size is relatively small.